本地快速开始¶
Anylearn后端引擎对算法的训练执行、训练跟踪、验证、模型的在线服务 等功能均制定了一系列的接口标准,以保障算法、模型的质量,做到“开箱即用”。 集成到Anylearn算法库/模型库的算法/模型均经过了标准化封装。
而对于用户自定义的算法、模型, 这套标准则会为使用Anylearn带来一定的门槛。
而且,内置标准算法的预定义执行环境也较为严苛, 对于执行多样的自定义算法相对困难。
因此,Anylearn为自定义算法/模型的训练、验证、服务均提供了一套更为宽松的执行环境, 最大限度地降低了对算法格式的要求, 仅需提供:
依赖项列表(
requirements.txt)入口命令(例如
python3 main.py --train)输出路径(例如
./output/model)
即可执行训练或验证。
注解
本地模型服务仍在持续设计开发中,后续更新
在此基础之上, SDK还将 资源(算法、数据集、模型等等)注册、 资源上传、 项目创建、 任务创建等一系列 Anylearn训练、验证所必须的流程封装成用户接口, 仅需一次调用并传入相应的参数, 即可快速实现在Anylearn上启动训练或验证任务。
快速训练接口¶
-
anylearn.applications.quickstart.quick_train(algorithm_id: Optional[str] = None, algorithm_name: Optional[str] = None, algorithm_dir: Optional[Union[str, pathlib.Path]] = None, algorithm_force_update: bool = False, algorithm_git_ref: Optional[str] = None, dataset_hyperparam_name: str = 'dataset', dataset_id: Optional[Union[List[str], str]] = None, dataset_dir: Optional[Union[str, pathlib.Path]] = None, dataset_archive: Optional[str] = None, model_hyperparam_name: str = 'model', model_id: Optional[Union[List[str], str]] = None, pretrain_hyperparam_name: str = 'pretrain', pretrain_task_id: Optional[Union[List[str], str]] = None, project_id: Optional[str] = None, project_name: Optional[str] = None, entrypoint: Optional[str] = None, output: Optional[str] = None, mirror_name: Optional[str] = 'QUICKSTART', resource_uploader: Optional[anylearn.interfaces.resource.resource_uploader.ResourceUploader] = None, resource_polling: Union[float, int] = 5, hyperparams: dict = {}, hyperparams_prefix: str = '--', hyperparams_delimeter: str = ' ', resource_request: Optional[List[Dict[str, Dict[str, int]]]] = None, quota_group_name: Optional[str] = None, quota_group_request: Optional[Dict[str, int]] = None, task_description: Optional[str] = None, num_nodes: Optional[int] = 1, nproc_per_node: Optional[int] = 1)[源代码]¶ 本地算法快速训练接口。
仅需提供本地资源和训练相关的信息, 即可在Anylearn后端引擎启动自定义算法/数据集的训练:
算法路径(文件目录或压缩包)
数据集路径(文件目录或压缩包)
训练启动命令
训练输出路径
训练超参数
本接口封装了Anylearn从零启动训练的一系列流程:
算法注册、上传
数据集注册、上传
训练项目创建
训练任务创建
本地资源初次在Anylearn注册和上传时, 会在本地记录资源的校验信息。 下一次调用快速训练或快速验证接口时, 如果提供了相同的资源信息, 则不再重复注册和上传资源, 自动复用远程资源。
如有需要,也可向本接口传入已在Anylearn远程注册的算法或数据集的ID, 省略资源创建的过程。
- 参数
algorithm_id (
str, optional) – 已在Anylearn远程注册的算法ID。algorithm_name (
str, optional) – 指定的算法名称。 注:同一用户的自定义算法的名称不可重复。 如有重复,则复用已存在的同名算法, 算法文件将被覆盖并提升版本。 原有版本仍可追溯。algorithm_dir (
str, optional) – 本地算法目录路径。algorithm_git_ref (
str, optional) – 算法Gitea代码仓库的版本号(可以是commit号、分支名、tag名)。 使用本地算法时,如未提供此参数,则取本地算法当前分支名。algorithm_force_update (
bool, optional) – 在同步算法的过程中是否强制更新算法,如为True,Anylearn会对未提交的本地代码变更进行自动提交。默认为False。dataset_hyperparam_name (
str, optional) – 启动训练时,数据集路径作为启动命令参数传入算法的参数名。 需指定长参数名,如--data,并省略--部分传入。 数据集路径由Anylearn后端引擎管理。 默认为dataset。dataset_id (
str, optional) – 已在Anylearn远程注册的数据集ID。dataset_dir (
str, optional) – 本地数据集目录路径。dataset_archive (
str, optional) – 本地数据集压缩包路径。model_hyperparam_name (
str, optional) – 启动训练时,模型路径作为启动命令参数传入算法的参数名。 需指定长参数名,如--model,并省略--部分传入。 模型路径由Anylearn后端引擎管理。 默认为model。model_id (
str, optional) – 已在Anylearn远程注册/转存的模型ID。pretrain_hyperparam_name (
str, optional) – 启动训练时,前置训练结果(间接抽象为“预训练”,即”pretrain”)路径作为启动命令参数传入算法的参数名。 需指定长参数名,如--pretrain,并省略--部分传入。 预训练结果路径由Anylearn后端引擎管理。 默认为pretrain。pretrain_task_id (
List[str]|str, optional) – 在Anylearn进行过的训练的ID,一般为前缀TRAI的32位字符串。 Anylearn会对指定的训练进行结果抽取并挂载到新一次的训练中。project_id (
str, optional) – 已在Anylearn远程创建的训练项目ID。entrypoint (
str, optional) – 启动训练的入口命令。output (
str, optional) – 训练输出模型的相对路径(相对于算法目录)。resource_uploader (
ResourceUploader, optional) – 资源上传实现。 默认使用系统内置的同步上传器SyncResourceUploader。resource_polling (
float|int, optional) – 资源上传中轮询资源状态的时间间隔(单位:秒)。 默认为5秒。hyperparams (
dict, optional) – 训练超参数字典。 超参数将作为训练启动命令的参数传入算法。 超参数字典中的键应为长参数名,如--param,并省略--部分传入。 如需要标识类参数(flag),可将参数的值设为空字符串,如{'my-flag': ''},等价于--my-flag传入训练命令。 默认为空字典。hyperparams_prefix (
str, optional) – 训练超参数键前标识,可支持hydra特殊命令行传参格式的诸如+key1、++key2、 空前置key3等需求, 默认为--。
:param hyperparams_delimeter
str: 训练超参数键值间的分隔符,默认为空格 :obj:` ` 。 :param optional: 训练超参数键值间的分隔符,默认为空格 :obj:` ` 。 :param resource_request: 训练所需计算资源的请求。如未填,则使用Anylearn后端的
default资源组中的默认资源套餐。 自0.13.1版本起,此参数被标记为废弃,将于0.14.0版本中移除。 请使用quota_group_name和quota_group_request作为替代。0.13.1 版后已移除: use
quota_group_nameandquota_group_requestinstead. remove in 0.14.0.- 参数
quota_group_name (
str, optional) – 训练所需计算资源组名称或ID。quota_group_request (
dict, optional) – 训练所需计算资源组中资源数量。 若quota_group_name和quota_group_request有其一未填,则使用Anylearn后端的default资源组中的默认资源套餐。task_description (
str, optional) – 训练任务详细描述。 若值为非空, 且参数algorithm_force_update为True时, 则Anylearn在自动提交本地算法变更时, 会将此值作为commit message同步至远端num_nodes (
int, optional) – 分布式训练需要的节点数。nproc_per_node (
int, optional) – 分布式训练每个节点运行的进程数。
- 返回
TrainTask – 创建的训练任务对象
Algorithm – 在快速训练过程中创建或获取的算法对象
Dataset – 在快速训练过程中创建或获取的数据集对象
Project – 创建的训练项目对象
附:快速训练流程如下图所示:
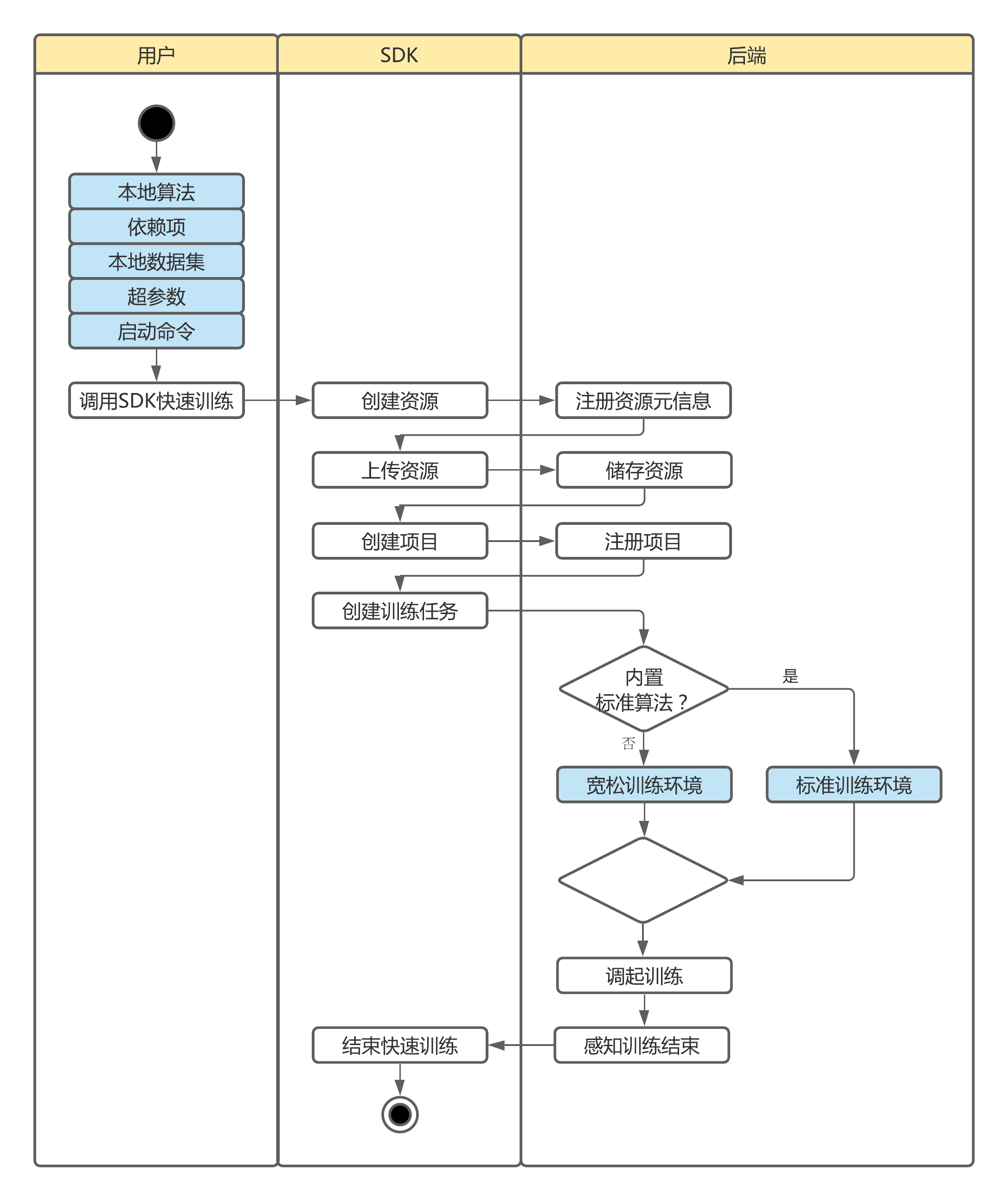
Anylearn SDK快速训练流程图¶