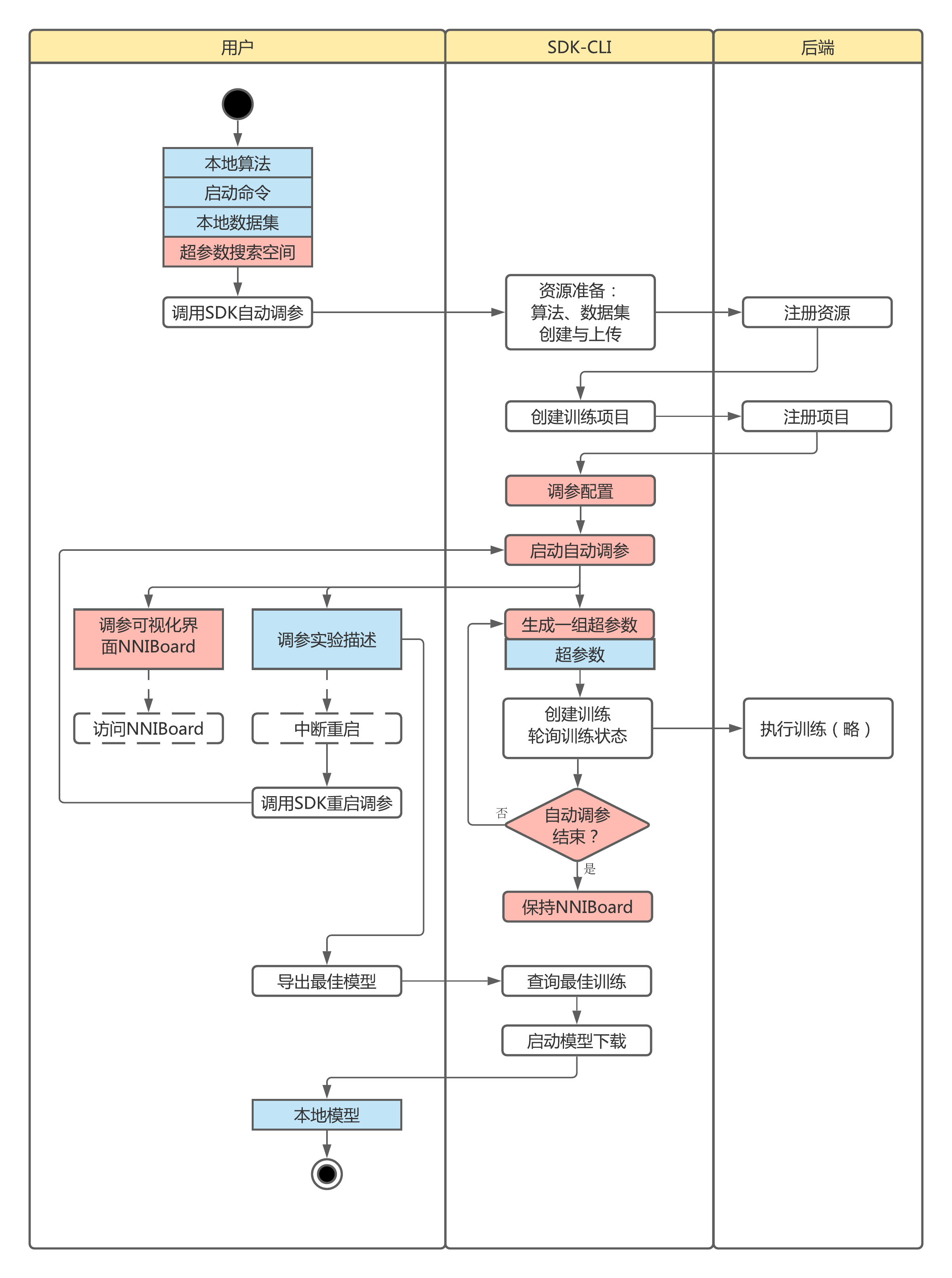
超参数自动调优¶
基于Anylearn后端引擎提供的强大的训练和任务管理能力, 借助开源工具 NNI , Anylearn SDK提供了一套便捷使用超参数自动调优的接口, 不仅支持Anylearn算法库内置标准算法, 也支持用户本地自定义的外置算法和数据集。
注解
超参数调优的相关概念参见 AutoML.org超参数调优 。
用户使用超参数自动调优的前提是对目标算法有基本的认知, 熟悉算法的所有超参数的类型、格式以及取值范围。 另外,不同超参数对算法效果的影响也不尽相同, 了解算法的哪些超参数有调优价值会使自动调优的过程更加高效。
超参数自动调优的本质是最优化过程, 其使用的优化方法大多是搜索类算法,如:随机搜索、网格搜索等等。 因此,使用超参数自动调优时需要用户定义一个超参数搜索空间, 为每一个要调优的超参数定义一套取值方式和取值范围。 Anylearn SDK中集成了 开源工具 NNI 来统筹超参数自动调优过程, 并沿用了其超参数搜索空间的定义方式, 参见 NNI超参数搜索空间 。
调参过程中出了搜索空间之外还有其他一些配置项, 用以控制调参的时长、优化算法、本地执行环境等等。 目前接受的配置包括:
超参数搜索空间
最大调优任务数(到量终止调优)
最长调优总时间(到时终止调优)
调优算法
调优模式(最大化或最小化指标)
本地端口绑定
此外,SDK中提供了一套管理超参数自动调优实验的方法, 即 调参实验描述(profile)类 。 一个调参实验的描述包括了调参任务配置、训练配置以及算法、数据集、训练的元信息等几方面, 用户可以根据这些信息可以在多次调参实验之间进行区别和回忆。 调参实验描述中封装了一系列与实验相关的功能, 如:获取全部实验、获取某一实验、停止实验、重启实验、输出最佳模型等等, 以便对任一调参实验的生命周期进行完整的回溯和管理。
注解
版本 0.11.0 新特性:创建调参实验时,需要额外增加计算资源请求(单次训练)
超参数自动调优接口¶
-
anylearn.applications.hpo.run_hpo(hpo_search_space: dict, hpo_max_runs: int = 10, hpo_max_duration: str = '24h', hpo_tuner_name: str = 'TPE', hpo_mode: str = 'maximize', hpo_concurrency: int = 1, project_name: Optional[str] = None, algorithm_id: Optional[str] = None, algorithm_name: Optional[str] = None, algorithm_dir: Optional[str] = None, algorithm_archive: Optional[str] = None, algorithm_entrypoint: Optional[str] = None, algorithm_output: Optional[str] = None, mirror_name: Optional[str] = 'QUICKSTART', dataset_id: Optional[str] = None, dataset_dir: Optional[str] = None, dataset_archive: Optional[str] = None, resource_uploader: Optional[anylearn.interfaces.resource.resource_uploader.ResourceUploader] = None, resource_polling: Union[float, int] = 5, resource_timeout: Union[float, int] = 120, dataset_hyperparam_name: str = 'dataset', resource_request: Optional[List[Dict[str, Dict[str, int]]]] = None) → anylearn.applications.hpo_experiment.HpoExperiment[源代码]¶ 超参数自动调优接口。
仅需提供调优配置参数和本地资源相关信息, 即可在本地启动针对自定义算法/数据集的超参数自动调优, 调优过程中使用Anylearn后端引擎进行多次训练, 汇总到同一个训练项目中。
目前接受的调优配置包括(详情参见本接口参数列表):
超参数搜索空间
最大调优任务数(到量终止调优)
最长调优总时间(到时终止调优)
调优算法
调优模式(最大化或最小化指标)
端口绑定
与本地快速训练类似, 本接口封装了Anylearn从零启动训练的一些列流程。 参见
quick_train()。 此外,自动调优的配置和构建过程也封装在接口内。- 参数
hpo_search_space (
dict) – 超参数搜索空间,格式详询NNI文档。hpo_max_runs (
int, optional) – 最大调优任务数,达成即终止实验。默认为10。hpo_max_duration (
str, optional) – 最长调优总时间,达成即终止实验。 格式为数字 + s|m|h|d, 例如: 半天0.5d, 十分钟10m。 默认为24h。hpo_tuner_name (
str, optional) – 调优算法名称。 详见 NNI内置调优算法 。 默认为TPE。hpo_mode (
str, optional) – 调优模式,即,最大化或最小化指标。 可选项:maximize或minimize。 默认为maximize。hpo_concurrency (
int, optional) – 调优期望并行度,即期望同时运行的任务数,实际并行度视后端资源调度情况而定。 默认为1。project_name (
str, optional) – 将要创建的训练项目名称。如已传远程project_id则忽略。algorithm_id (
str, optional) – 已在Anylearn远程注册的算法ID。algorithm_name (
str, optional) – 指定的算法名称。 注:同一用户的自定义算法的名称不可重复。 如有重复,则复用已存在的同名算法, 算法文件将被覆盖并提升版本。 原有版本仍可追溯。algorithm_dir (
str, optional) – 本地算法目录路径。algorithm_archive (
str, optional) – 本地算法压缩包路径。algorithm_entrypoint (
str, optional) – 启动训练的入口命令。algorithm_output (
str, optional) – 训练输出模型的相对路径(相对于算法目录)。mirror_name (
str, optional) – 快速训练镜像名,默认为QUICKSTART。dataset_id (
str, optional) – 已在Anylearn远程注册的数据集ID。dataset_dir (
str, optional) – 本地数据集目录路径。dataset_archive (
str, optional) – 本地数据集压缩包路径。resource_uploader (
ResourceUploader, optional) – 资源上传实现。 默认使用系统内置的同步上传器SyncResourceUploader。resource_polling (
float|int, optional) – 资源上传中轮询资源状态的时间间隔(单位:秒)。 默认为5秒。resource_timeout (
float|int, optional) – 轮询状态的超时时长(单位:秒)。 默认为120秒。dataset_hyperparam_name (
str, optional) – 启动训练时,数据集路径作为启动命令参数传入算法的参数名。 需指定长参数名,如--data,并省略--部分传入。 数据集路径由Anylearn后端引擎管理。 默认为dataset。hyperparams (
dict, optional) – 训练超参数字典。 超参数将作为训练启动命令的参数传入算法。 超参数字典中的键应为长参数名,如--param,并省略--部分传入。 默认为空字典。resource_request (
List[Dict[str, Dict[str, int]]], optional) – 单次训练所需计算资源的请求。 如未填,则使用Anylearn后端的:obj:`default`资源组中的默认资源套餐。
- 返回
调参实验对象
- 返回类型
调参实验描述(profile)类¶
-
class
anylearn.applications.hpo_experiment.HpoExperiment(project_id: str, algorithm_id: Optional[str] = None, dataset_id: Optional[str] = None, hpo_search_space: Optional[dict] = None, hpo_max_runs: Optional[int] = 10, hpo_max_duration: Optional[int] = '24h', hpo_tuner_name: Optional[str] = 'TPE', hpo_mode: Optional[str] = 'maximize', hpo_concurrency: Optional[int] = 1, resource_request: Optional[List[Dict[str, Dict[str, int]]]] = None, created_at: Optional[datetime.datetime] = datetime.datetime(2022, 12, 29, 0, 23, 17, 427360), hpo_id: Optional[str] = None, hpo_ip: Optional[str] = None, hpo_port: Optional[int] = None, hpo_status: Optional[str] = None, project: Optional[anylearn.interfaces.project.Project] = None, algorithm: Optional[anylearn.interfaces.resource.algorithm.Algorithm] = None, dataset: Optional[anylearn.interfaces.resource.dataset.Dataset] = None, dataset_hyperparam_name: Optional[str] = 'dataset', tasks: Optional[dict] = {}, err: Optional[list] = None, load_detail: bool = False)[源代码]¶ 调参实验描述类。
一个调参实验的描述包括了 调参任务配置、 训练配置以及算法、 数据集、 训练的元信息 等几方面, 用户可以根据这些信息可以在多次调参实验之间进行区别和回忆。 调参实验描述中封装了一系列与实验相关的功能, 如:获取全部实验、获取某一实验、停止实验、重启实验、输出最佳模型等等, 以便对任一调参实验的生命周期进行完整的回溯和管理。
-
project_id¶ 已在Anylearn远程创建的训练项目ID。
- Type
str
-
algorithm_id¶ 已在Anylearn远程注册的算法ID。
- Type
str
-
dataset_id¶ 已在Anylearn远程注册的数据集ID。
- Type
str
-
hpo_search_space¶ 超参数搜索空间,格式详询
NNI文档。- Type
dict
-
hpo_max_runs¶ 最大调优任务数,达成即终止实验。默认为
10。- Type
int, optional
-
hpo_max_duration¶ 最长调优总时间,达成即终止实验。 格式为
数字 + s|m|h|d, 例如: 半天0.5d, 十分钟10m。 默认为24h。- Type
str, optional
-
hpo_mode¶ 调优模式,即,最大化或最小化指标。 可选项:
maximize或minimize。- Type
str, optional
-
hpo_concurrency¶ 调优期望并行度,即期望同时运行的任务数,实际并行度视后端资源调度情况而定。 默认为
1。- Type
int, optional
-
resource_request¶ 单次训练所需计算资源的请求。 如未填,则使用Anylearn后端的:obj:`default`资源组中的默认资源套餐。
- Type
List[Dict[str, Dict[str, int]]], optional
-
created_at¶ 调参实验的创建时间。 默认为东八时区的当前时间。
- Type
str, optional
-
hpo_id¶ 调参实验ID。
- Type
str, optional
-
hpo_ip¶ 调参实验容器IP地址。
- Type
str, optional
-
hpo_port¶ 调优实验的本地端口绑定。
- Type
int, optional
-
project¶ 已在Anylearn远程创建的训练项目对象
- Type
Project, optional
-
algorithm¶ 已在Anylearn远程注册的算法对象。
- Type
Algorithm, optional
-
dataset¶ 已在Anylearn远程注册的数据集对象。
- Type
Dataset, optional
-
dataset_hyperparam_name¶ 启动训练时,数据集路径作为启动命令参数传入算法的参数名。 需指定长参数名,如
--data,并省略--部分传入。 数据集路径由Anylearn后端引擎管理。 默认为dataset。- Type
str, optional
-
tasks¶ 调参实验中的训练任务ID与调参任务ID的映射。
- Type
dict, optional
-
err¶ 调参准备过程中出现的错误日志。
- Type
list, optional
-
__init__(project_id: str, algorithm_id: Optional[str] = None, dataset_id: Optional[str] = None, hpo_search_space: Optional[dict] = None, hpo_max_runs: Optional[int] = 10, hpo_max_duration: Optional[int] = '24h', hpo_tuner_name: Optional[str] = 'TPE', hpo_mode: Optional[str] = 'maximize', hpo_concurrency: Optional[int] = 1, resource_request: Optional[List[Dict[str, Dict[str, int]]]] = None, created_at: Optional[datetime.datetime] = datetime.datetime(2022, 12, 29, 0, 23, 17, 427360), hpo_id: Optional[str] = None, hpo_ip: Optional[str] = None, hpo_port: Optional[int] = None, hpo_status: Optional[str] = None, project: Optional[anylearn.interfaces.project.Project] = None, algorithm: Optional[anylearn.interfaces.resource.algorithm.Algorithm] = None, dataset: Optional[anylearn.interfaces.resource.dataset.Dataset] = None, dataset_hyperparam_name: Optional[str] = 'dataset', tasks: Optional[dict] = {}, err: Optional[list] = None, load_detail: bool = False)[源代码]¶ - 参数
project_id (
str) – 已在Anylearn远程创建的训练项目ID。algorithm_id (
str) – 已在Anylearn远程注册的算法ID。dataset_id (
str) – 已在Anylearn远程注册的数据集ID。hpo_search_space (
dict) – 超参数搜索空间,格式详询NNI文档。hpo_max_runs (
int, optional) – 最大调优任务数,达成即终止实验。默认为10。hpo_max_duration (
str, optional) – 最长调优总时间,达成即终止实验。 格式为数字 + s|m|h|d, 例如: 半天0.5d, 十分钟10m。 默认为24h。hpo_tuner_name (
str, optional) –调优算法名称。 详见 NNI内置调优算法 。 默认为
TPE。hpo_mode (
str, optional) – 调优模式,即,最大化或最小化指标。 可选项:maximize或minimize。hpo_concurrency (
int, optional) – 调优期望并行度,即期望同时运行的任务数,实际并行度视后端资源调度情况而定。 默认为1。resource_request (
List[Dict[str, Dict[str, int]]], optional) – 单次训练所需计算资源的请求。 如未填,则使用Anylearn后端的:obj:`default`资源组中的默认资源套餐。created_at (
str, optional) – 调参实验的创建时间。 默认为东八时区的当前时间。hpo_id (
str, optional) – 调参实验ID。hpo_ip (
str, optional) – 调参实验容器IP地址。hpo_port (
int, optional) – 调优实验的本地端口绑定。project (
Project, optional) – 已在Anylearn远程创建的训练项目对象algorithm (
Algorithm, optional) – 已在Anylearn远程注册的算法对象。dataset (
Dataset, optional) – 已在Anylearn远程注册的数据集对象。dataset_hyperparam_name (
str, optional) – 启动训练时,数据集路径作为启动命令参数传入算法的参数名。 需指定长参数名,如--data,并省略--部分传入。 数据集路径由Anylearn后端引擎管理。 默认为dataset。tasks (
dict, optional) – 调参实验中的训练任务ID与调参任务ID的映射。err (
list, optional) – 调参准备过程中出现的错误日志。
-
stop()[源代码]¶ 停止调参实验。
对象属性
project_id应为非空
-
resume()[源代码]¶ 重启调参实验。
对象属性
project_id应为非空
-
view()[源代码]¶ 启动调参可视化面板。
对象属性
project_id应为非空
-
get_log()[源代码]¶ 获取调参实验日志(nnimanager.log)。
对象属性
project_id应为非空
-
get_trial_logs()[源代码]¶ 获取调参实验日志(nnimanager.log)。
对象属性
project_id应为非空
-
get_best_train_task() → anylearn.interfaces.train_task.TrainTask[源代码]¶ 获取调参实验中取得最佳指标的训练任务。
对象属性
project_id应为非空
-
export_best_model(local_save_path: str, downloader: Optional[anylearn.interfaces.resource.resource_downloader.ResourceDownloader] = None)[源代码]¶ 导出调参实验中取得最佳指标的模型至本地(下载)。
对象属性
project_id应为非空
- 参数
local_save_path (
str) – 模型下载的本地保存路径。downloader (
ResourceDownloader, optional) – 模型下载器实现对象(建议留空)。 缺省时将实例化一个内置的异步下载器。
-
transform_best_model(model_name: str, model_description: Optional[str] = None, model_transform_polling: Union[float, int] = 5) → anylearn.interfaces.resource.model.Model[源代码]¶ 转存调参实验中取得最佳指标的模型至Anylearn后端引擎。
注解
训练的输出文件夹将被完整转存。
- 参数
model_name (
str) – 模型名称。model_description (
str, optional) – 模型描述。 默认为空。model_transform_polling (
float|int, optional) – 模型转存过程中,轮询模型转存状态的时间间隔。 默认为5秒。
- 返回
最佳模型转存后的对象。
- 返回类型
-
classmethod
load(data: dict, load_detail=False)[源代码]¶ 从接口返回值映射对一个调参实验描述进行实例化。
- 参数
data (
dict) – 以字典承载的调参实验元信息。- 返回
调参实验描述对象。
- 返回类型
-