CLI快速入门教程¶
本节目录
注解
CLI需配合Anylearn账号使用,如未注册,请先移步相应的Anylearn前端创建账号。
注解
SDK/CLI的安装指南请参考 安装
初始化本地项目¶
Anylearn CLI以用户本地目录为边界来管理训练实验、数据集、算法等等。
用户可以在任一本地目录执行CLI的 anyctl init 命令初始化Anylearn项目。
建议用户为每个不同的项目单独开辟一个本地项目目录。
cd /path/to/desired/workspace
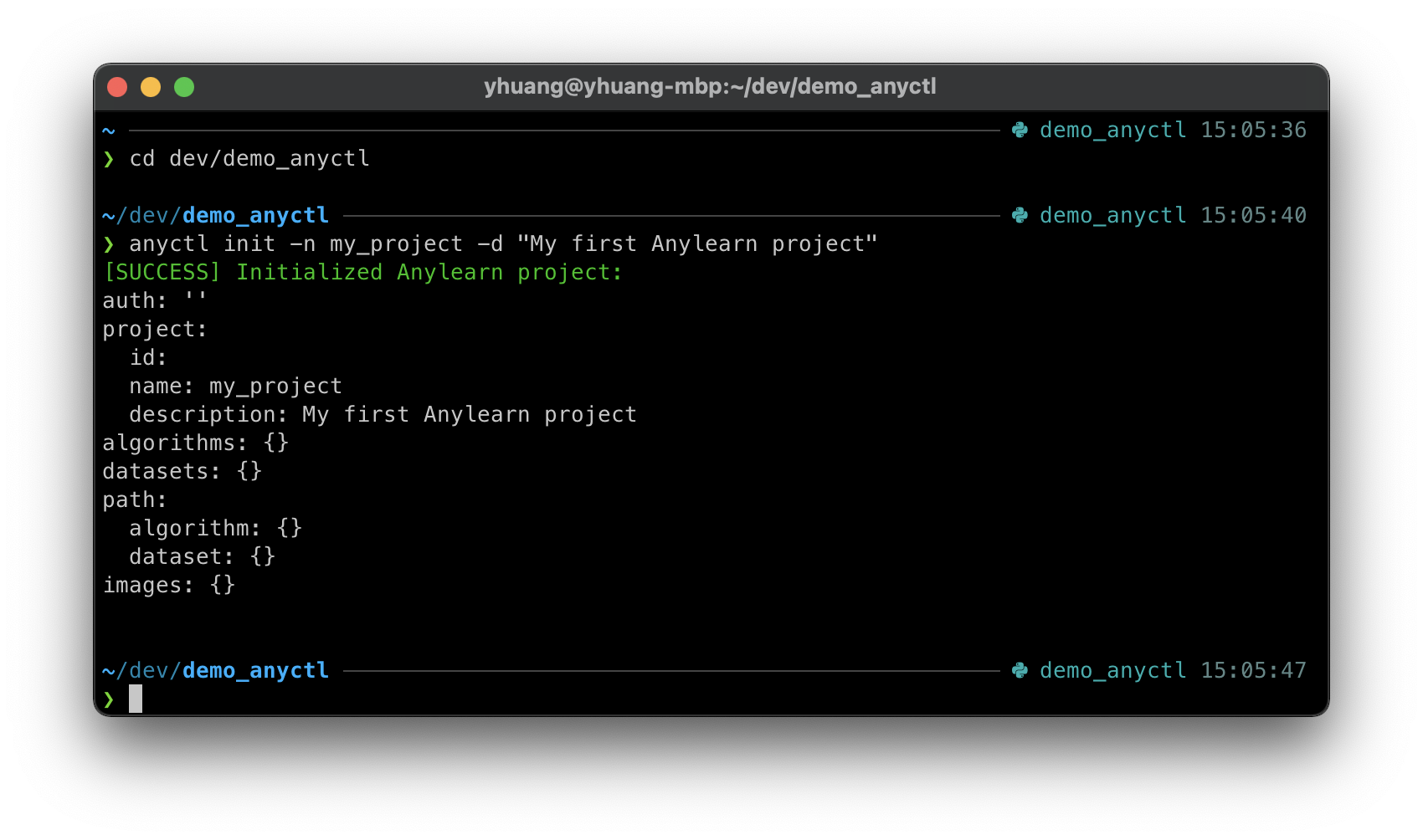
anyctl init -n my_project -d "My first Anylearn project"
其中:
可通过 -n 或 --project-name 选项指定项目名称,未指定时默认使用当前目录名;
可通过 -d 或 --description 选项指定项目描述,未指定则留空。
运行后会有以下输出:
从CLI登录Anylearn¶
完成本地项目初始化后,可通过 anyctl login 命令与远端Anylearn建立连接。
CLI会以交互式的方式向用户询问连接相关信息(Anylearn地址、用户名、密码)。
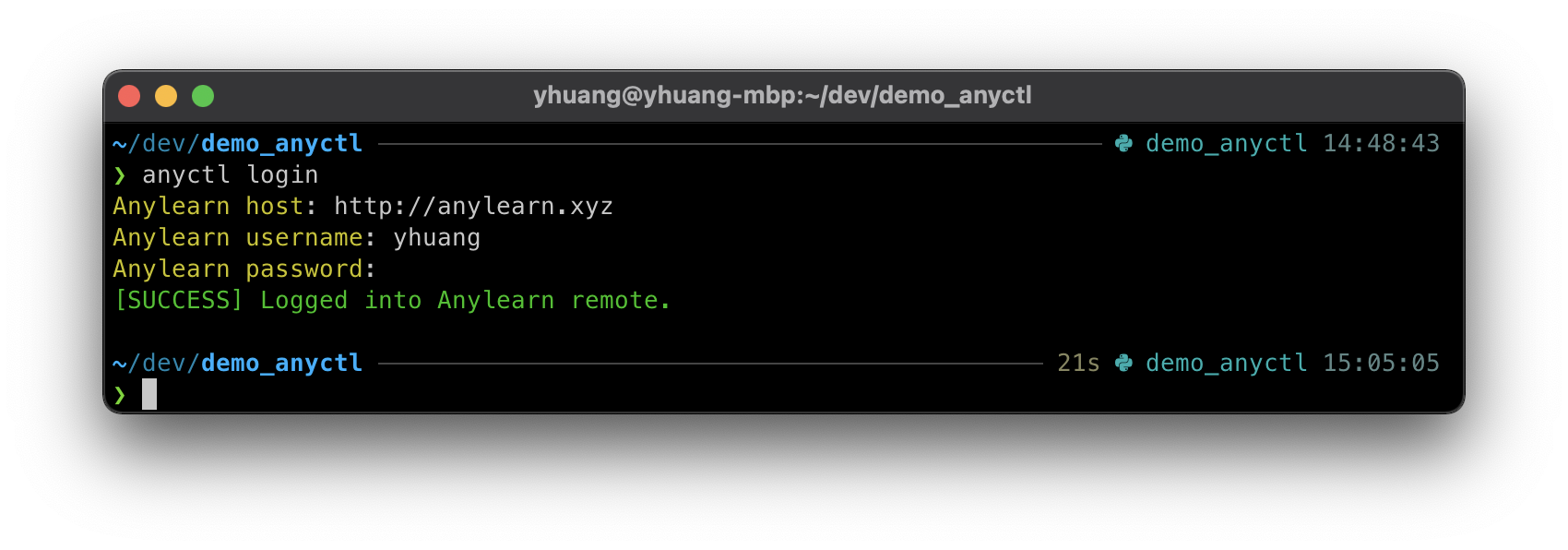
anyctl login
运行后会有以下输出:
注解
用户亦可通过在 anyctl init 命令中指明 --login 选项
在初始化本地项目的同时登录到Anylearn:
anyctl init -n my_project -d "My first Anylearn project" --login
添加本地算法¶
用户想要使用的算法,
无论是本地算法还是远端Anylearn中已存在的算法,
均需要通过 anyctl add algorithm 命令添加到本地项目中,
便于CLI进行管理。
这里以添加本地算法为例:
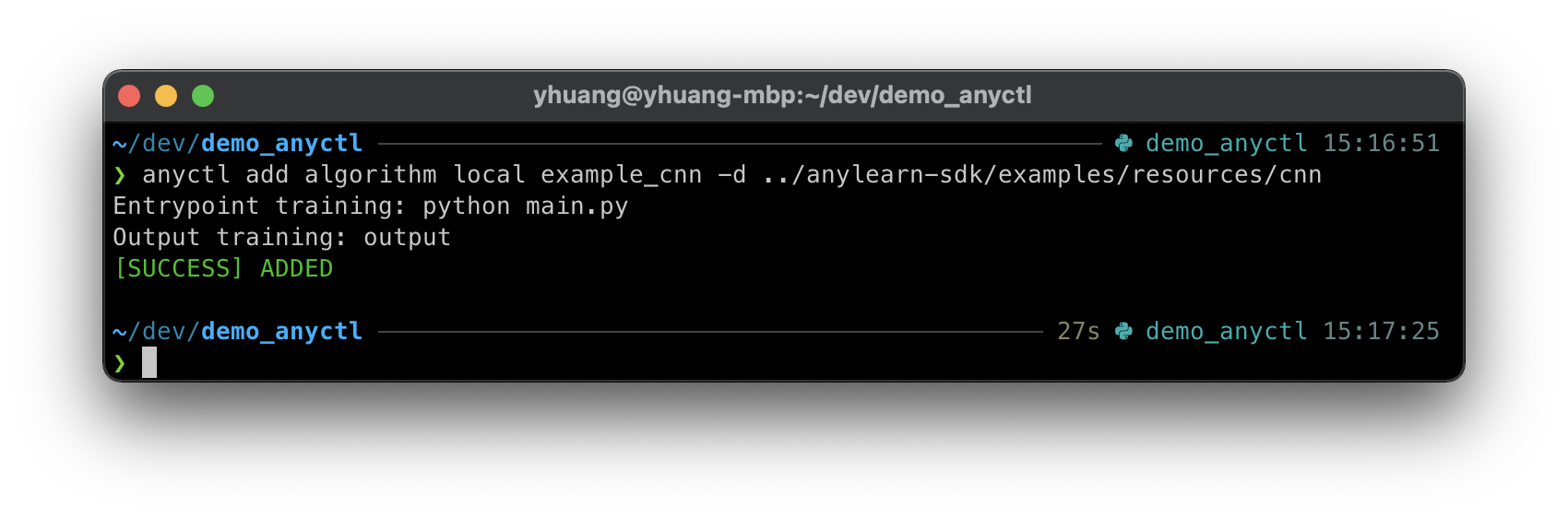
anyctl add algorithm local example_cnn -dir /path/to/local/algo
其中:
local 子命令表明当前需要添加的算法为本地算法,
用户需指明算法名称(即上述命令中的 example_cnn );
用户可通过 -d 或 --dir 选项指定本地算法所在目录。
运行后,CLI会以交互式的方式向用户询问算法运行的必要信息:
注解
用户亦可通过 --entrypoint-training <command> 和 --output-training <dir> 选项来
指定算法运行的入口命令和输出目录(替换上述 <command> 和 <dir> 为真实值):
anyctl add algorithm local example_cnn -dir /path/to/local/algo --entrypoint-training "python main.py" --output-training outpu
添加本地数据集(若无需要可忽略)¶
类似地,本地数据集或远端Anylearn中已存在的数据集,
亦需通过 anyctl add dataset 命令添加到本地项目中,
便于CLI进行管理。
这里以添加本地数据集为例:
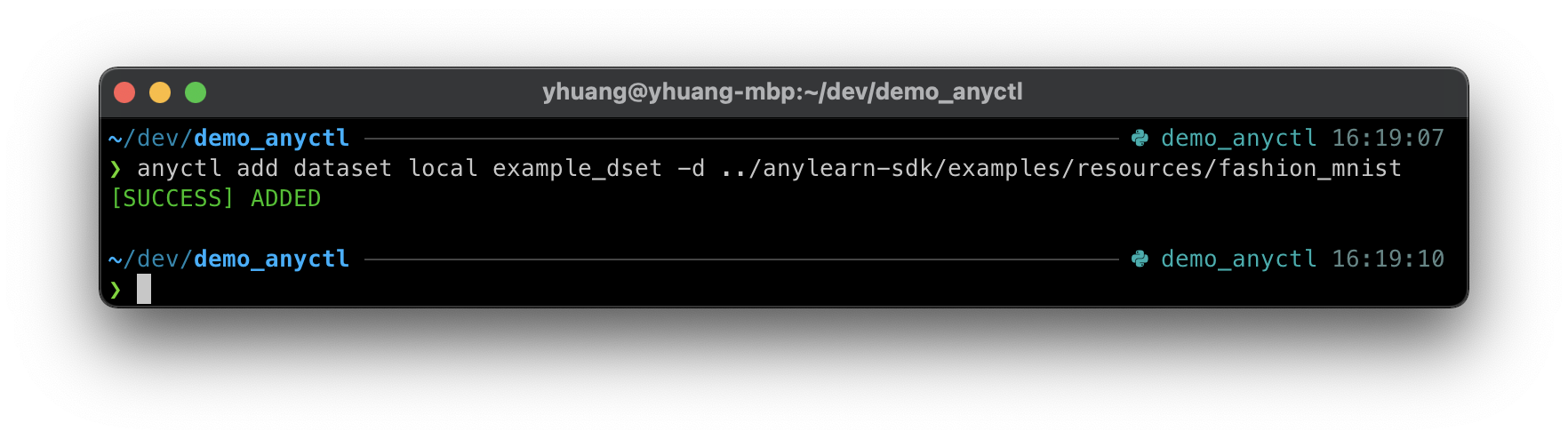
anyctl add dataset local example_dset --dir /path/to/local/dataset
其中:
local 子命令表明当前需要添加的数据集为本地数据集,
用户需指明数据集名称(即上述命令中的 example_dset );
用户可通过 -d 或 --dir 选项指定本地数据集所在目录。
运行后会有以下输出:
查看本地项目配置¶
用户可以通过 anyctl config ls 命令来查看当前本地项目下的全部配置:
anyctl config ls
运行后会有以下输出:
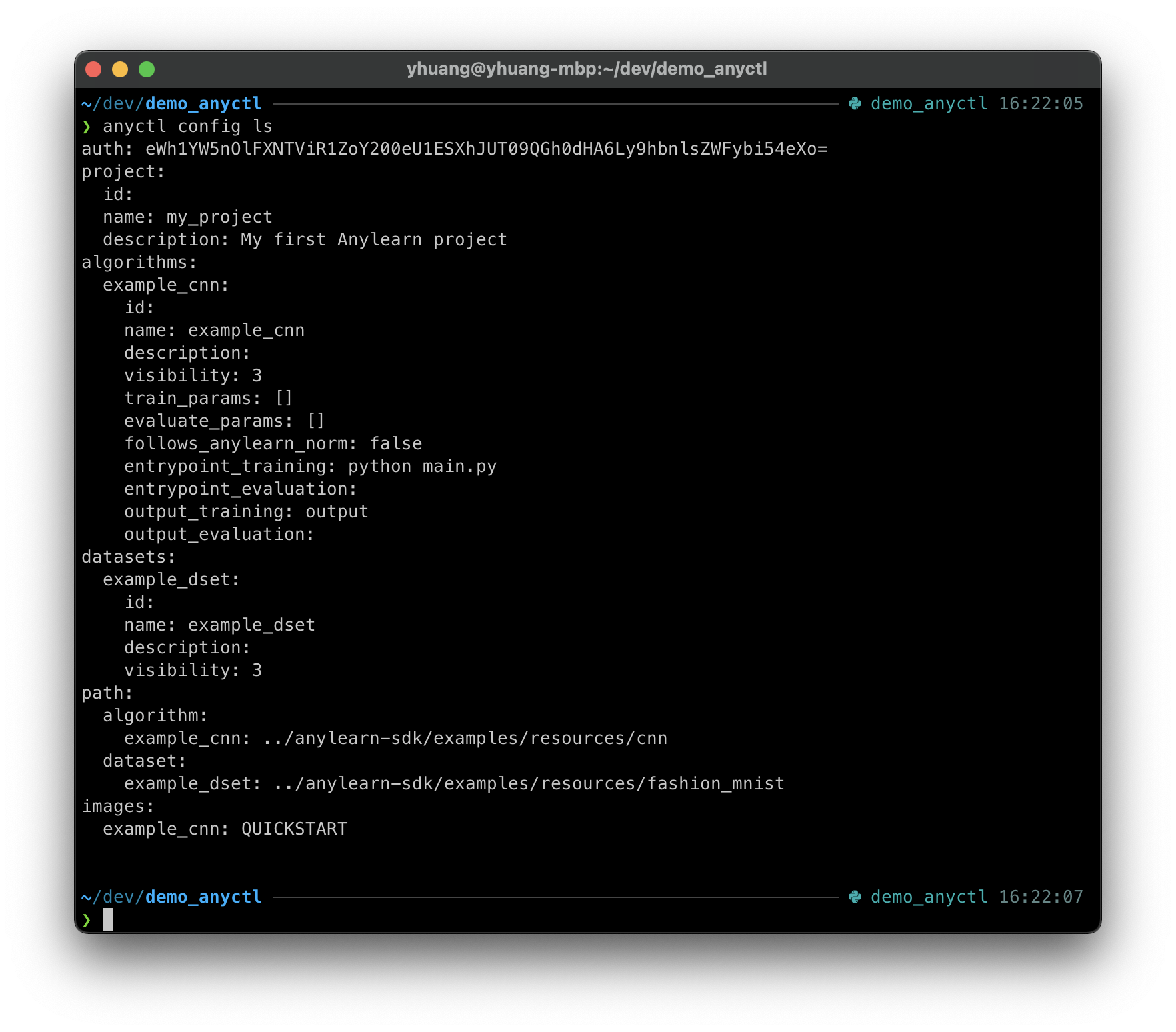
项目配置主要分为6个部分:
auth后端连接信息project项目元信息algorithms项目中已添加的算法列表和算法元信息datasets项目中已添加的数据集列表和数据集元信息path项目中本地算法和数据集的路径images项目中本地算法的计算镜像名称
其中,算法列表、数据集列表、路径、镜像等配置均以算法或数据集的名称作为键名。
注解
Anylearn CLI以项目配置的方式管理本地项目,
存放在每个本地项目目录下的 AnylearnProject.yaml 文件中,
用户可直接查看该文件,
熟悉Anylearn CLI的用户亦可直接编辑该配置文件。
同步资源¶
在将本地项目、算法、数据集同步到远端Anylearn之前
项目ID、添加的本地算法ID和数据集ID均为空,
如上述项目配置中所示。
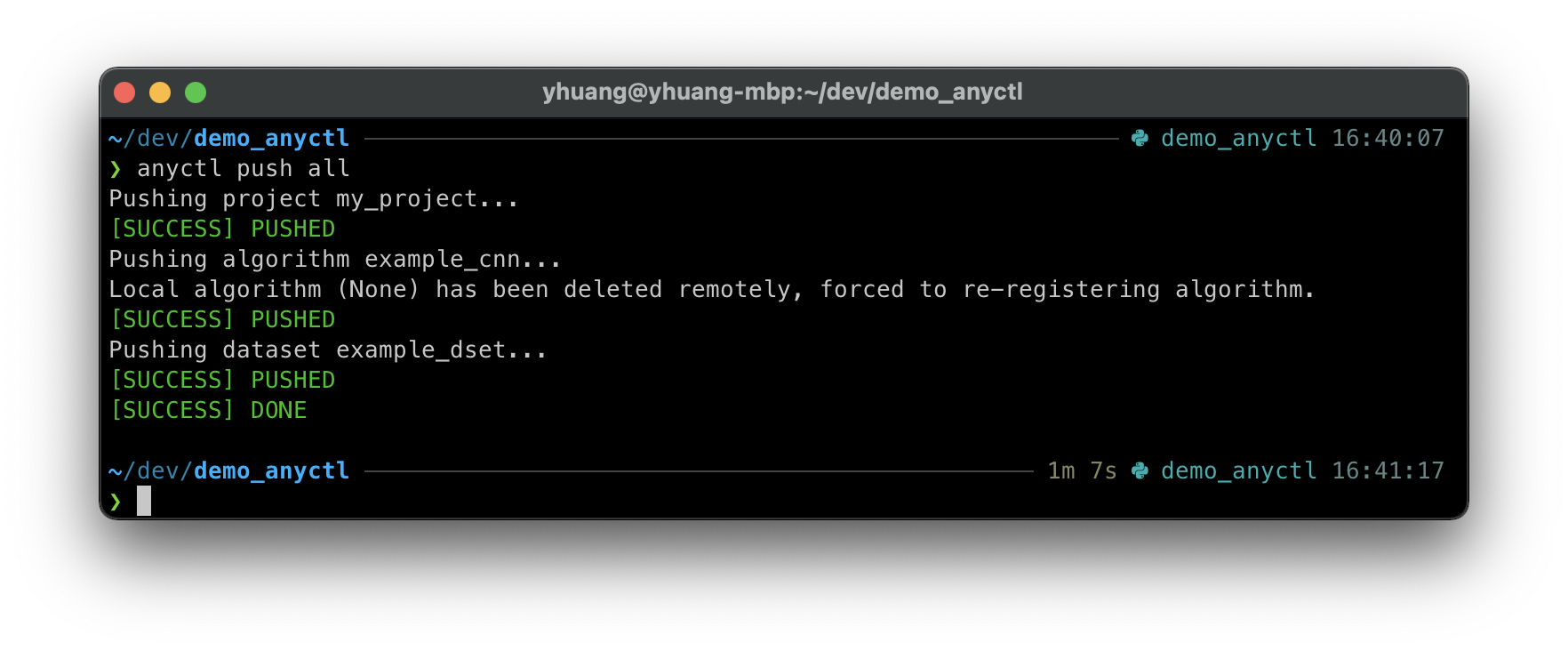
用户可通过 anyctl push 命令来进行同步。
anyctl push all
运行后会有以下输出:
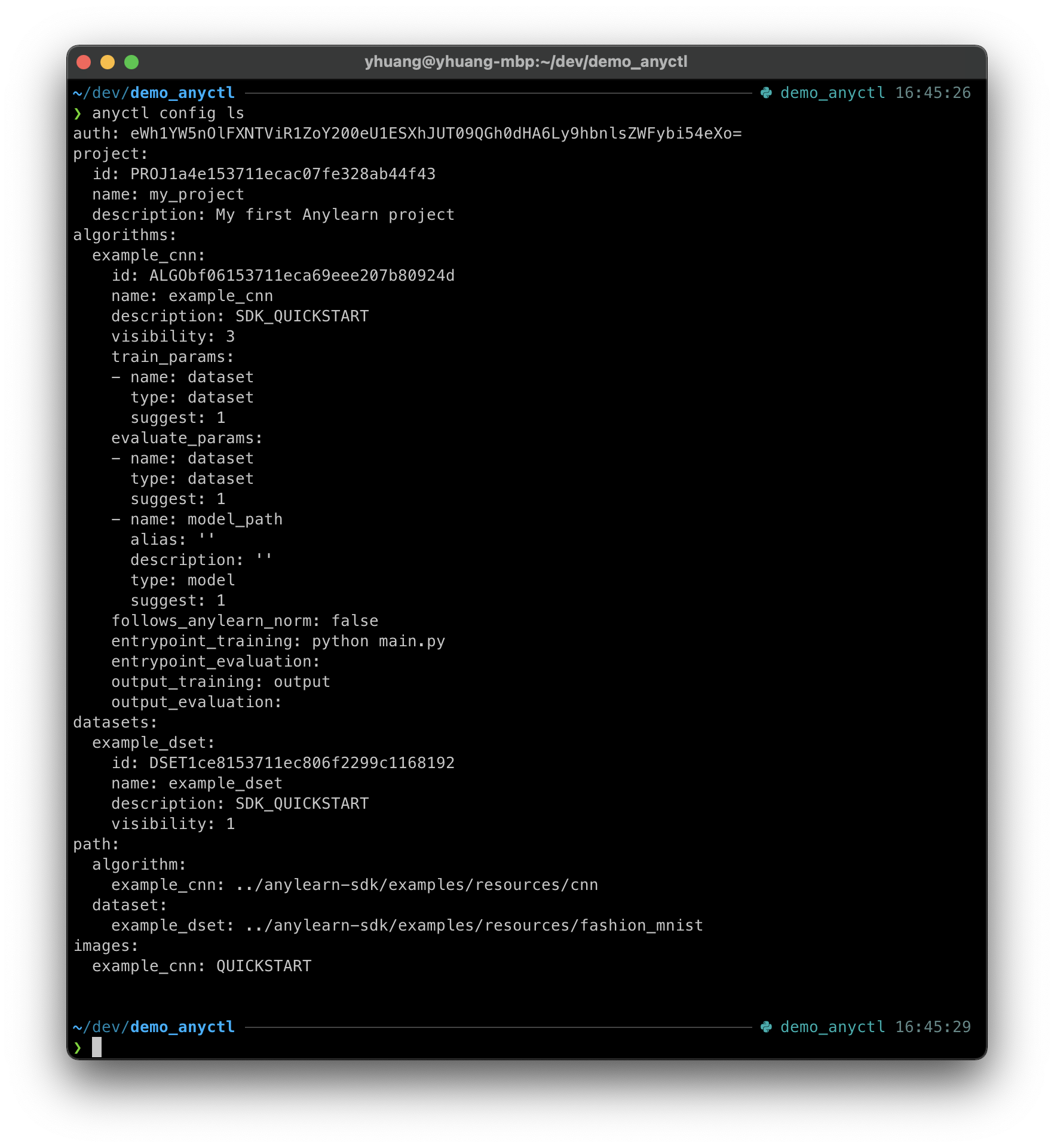
此时再次通过 anyctl config ls 命令查看项目配置即可查询到项目、算法和数据集的ID。
计算资源¶
从 0.11.0 版本开始,Anylearn中采用了全新的计算资源管理体系,
每位用户将会分配到一个或多个“资源组”,
运行训练时需指明资源组和所需的计算资源(CPU、GPU、内存等)。
用户可以通过 anyctl quota ls 命令查看所属资源组的当前状态:
anyctl quota ls
运行后会有以下输出:
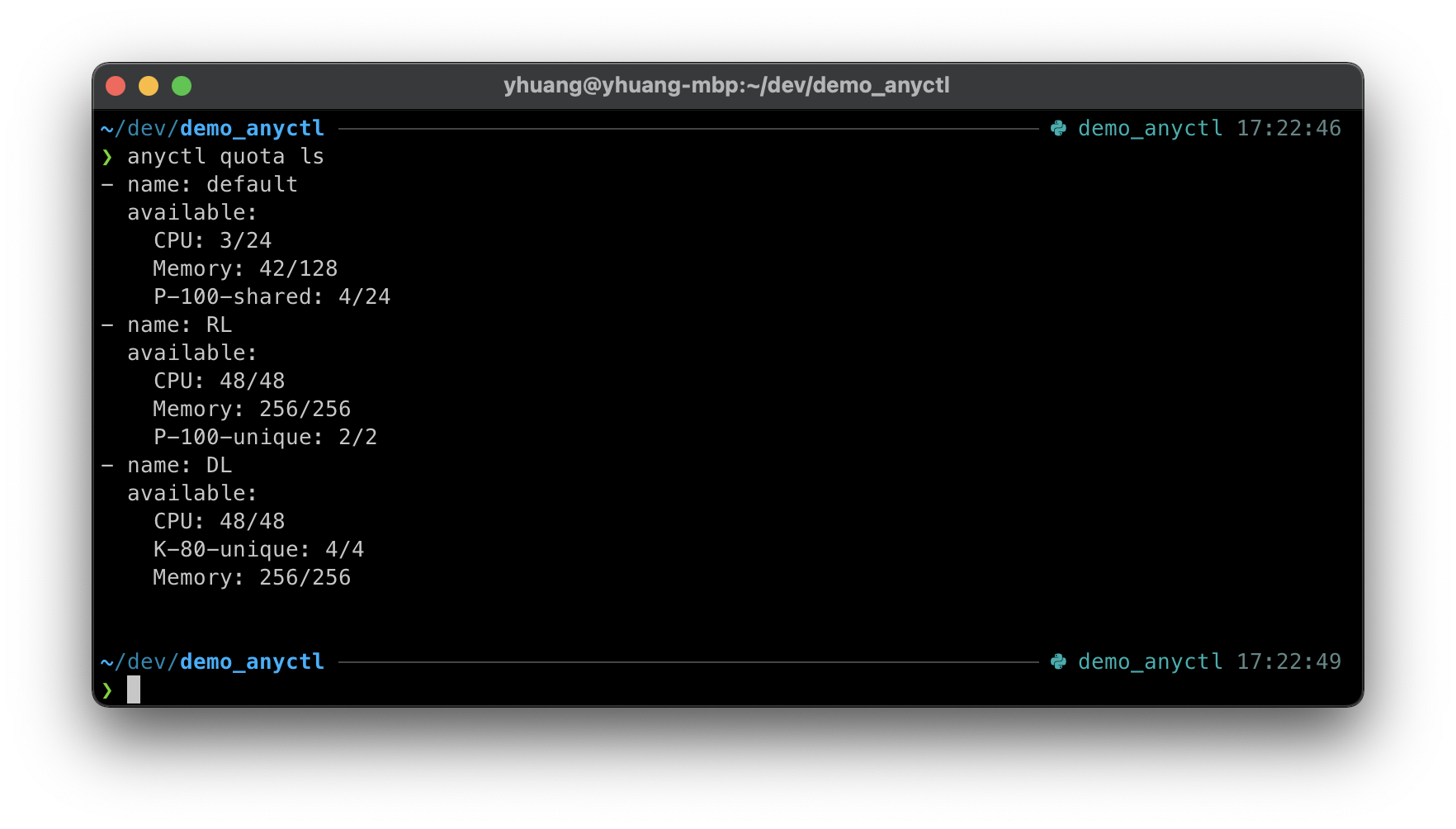
如上图所示,该用户可使用3个资源组: default 、 RL 和 DL ,
每个资源组分别展示了可用计算资源的数量,
例如, default 资源组中可用的CPU核数为3个,总共有24个。
注解
default 资源组默认分配到所有用户,其可控的计算资源非常有限。
其他特殊的资源组需向管理员申请,由管理员分配。
用户可以通过 anyctl quota template 命令,
在本地项目中创建某资源组的计算资源使用请求配置模板,
并按实际需求对其加以编辑,
在后续执行训练时可以指明这个配置文件来发送资源请求:
anyctl quota template DL
运行后会有以下输出:
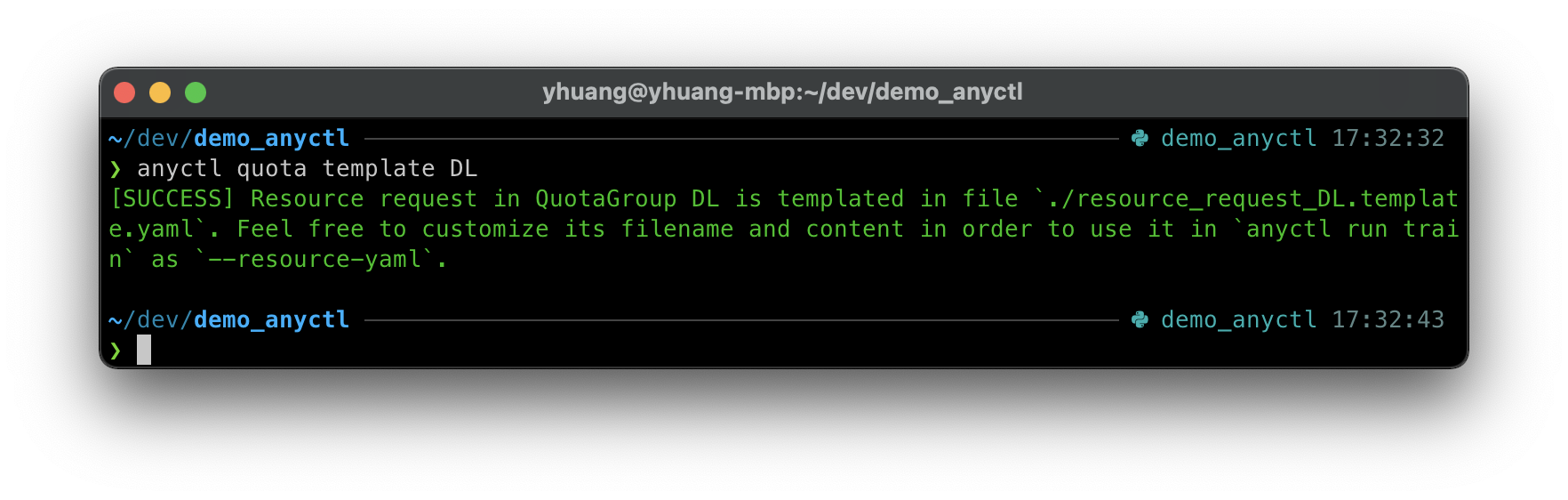
资源请求模板内容:

这里将生成的配置模板的文件名改为 resource.yaml 方便后续使用:
mv resource_request_DL.template.yaml resource.yaml
训练¶
用户可以通过 anyctl run training 命令执行训练:
anyctl run training example_cnn -d data-path=example_dset -p batch-size=256 -p epochs=12
其中:
anyctl run training 命令的参数为算法名称,即上述命令中的 example_cnn;
用户可以通过 -d 或 --data 选项来指定训练所需的数据集,
该选项可多次指定,
格式为 <key-passed-to-algo>=<dataset-name>;
用户可以通过 -p 或 --param 选项来指定训练的超参数,
该选项可多次指定,
格式为 <key>=<value>。
运行后会有以下输出:
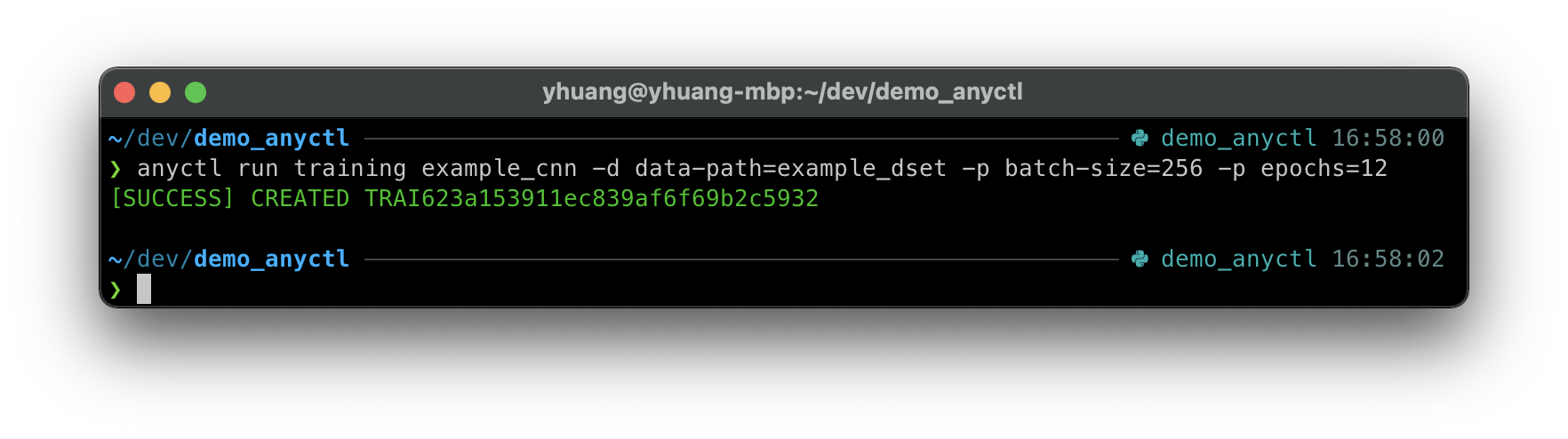
上述命令中没有使用资源请求,训练将会按 default 资源组中的默认资源请求进行调度。
用户亦可通过配置文件的方式指定训练所需的数据集和超参数。
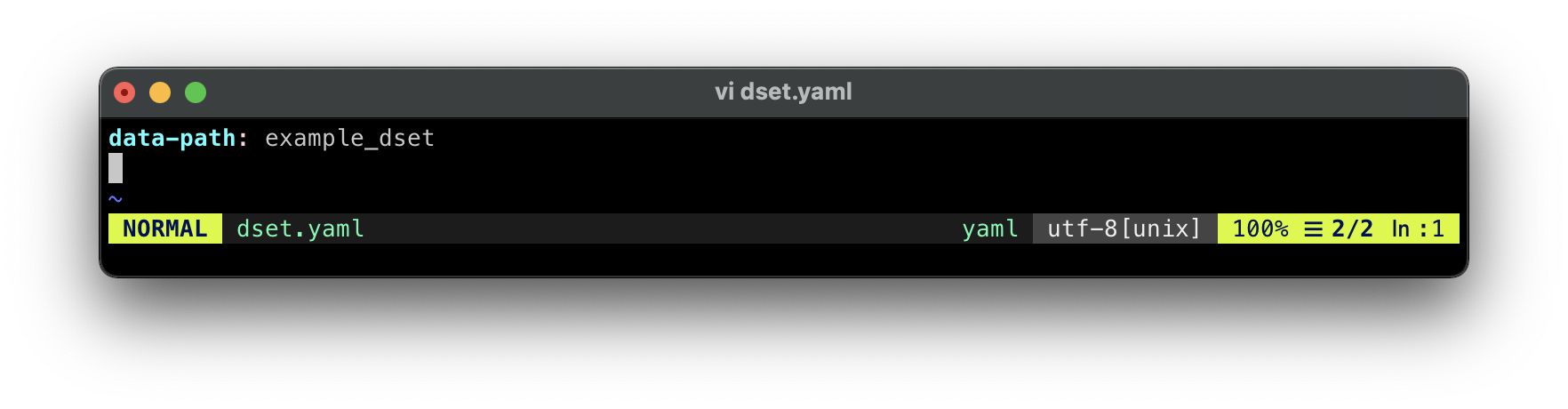
创建数据集配置文件:
vi dset.yaml
数据集配置文件内容:
data-path: example_dset
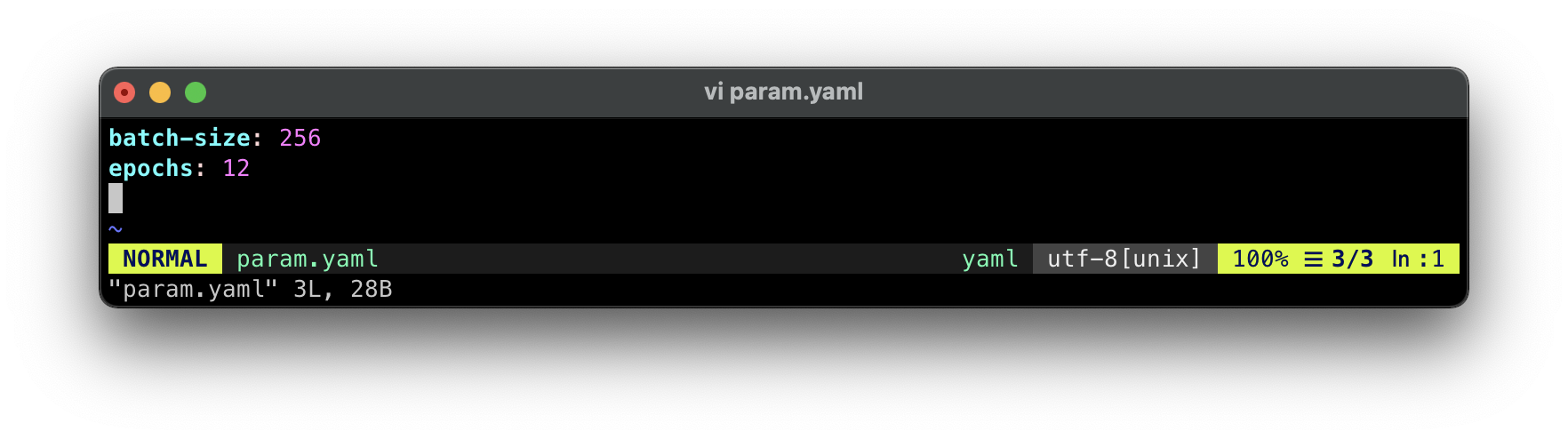
创建超参数配置文件:
vi param.yaml
超参数配置文件内容:
batch-size: 256
epochs: 12
搭配前面创建的计算资源配置文件,可以通过如下命令执行训练:
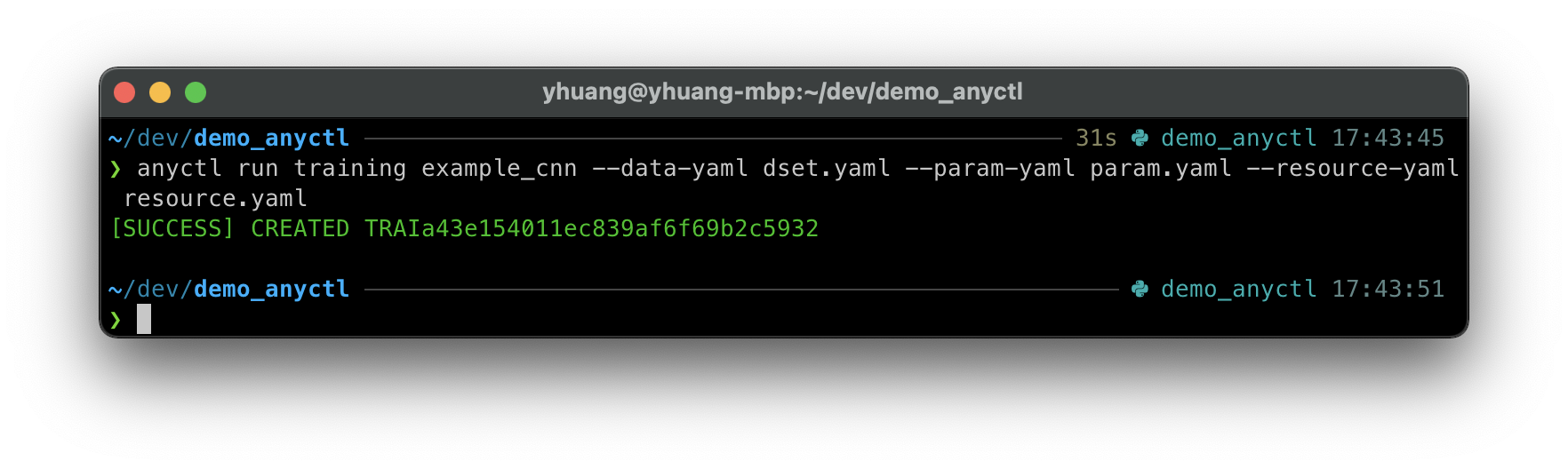
anyctl run training example_cnn --data-yaml dset.yaml --param-yaml param.yaml --resource-yaml resource.yaml
运行后会有以下输出:
查看训练任务¶
用户可以通过 anyctl task ls 命令查询当前项目中的所有训练任务:
anyctl task ls
运行后会有以下输出:
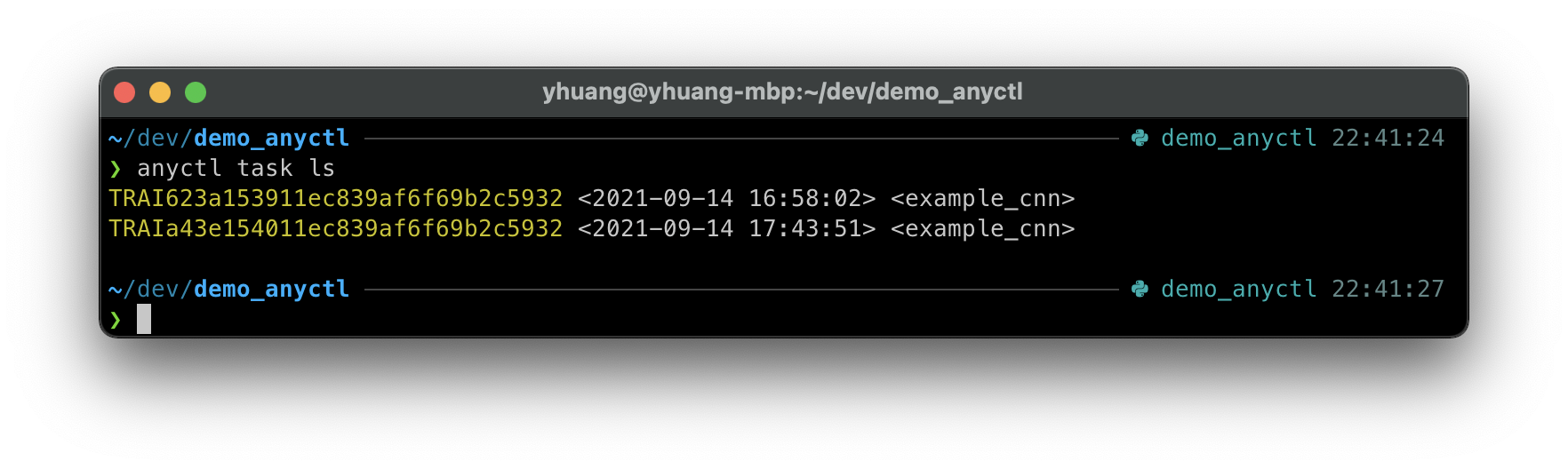
其中,高亮部分为训练任务ID,部分命令需提供此ID进行操作,
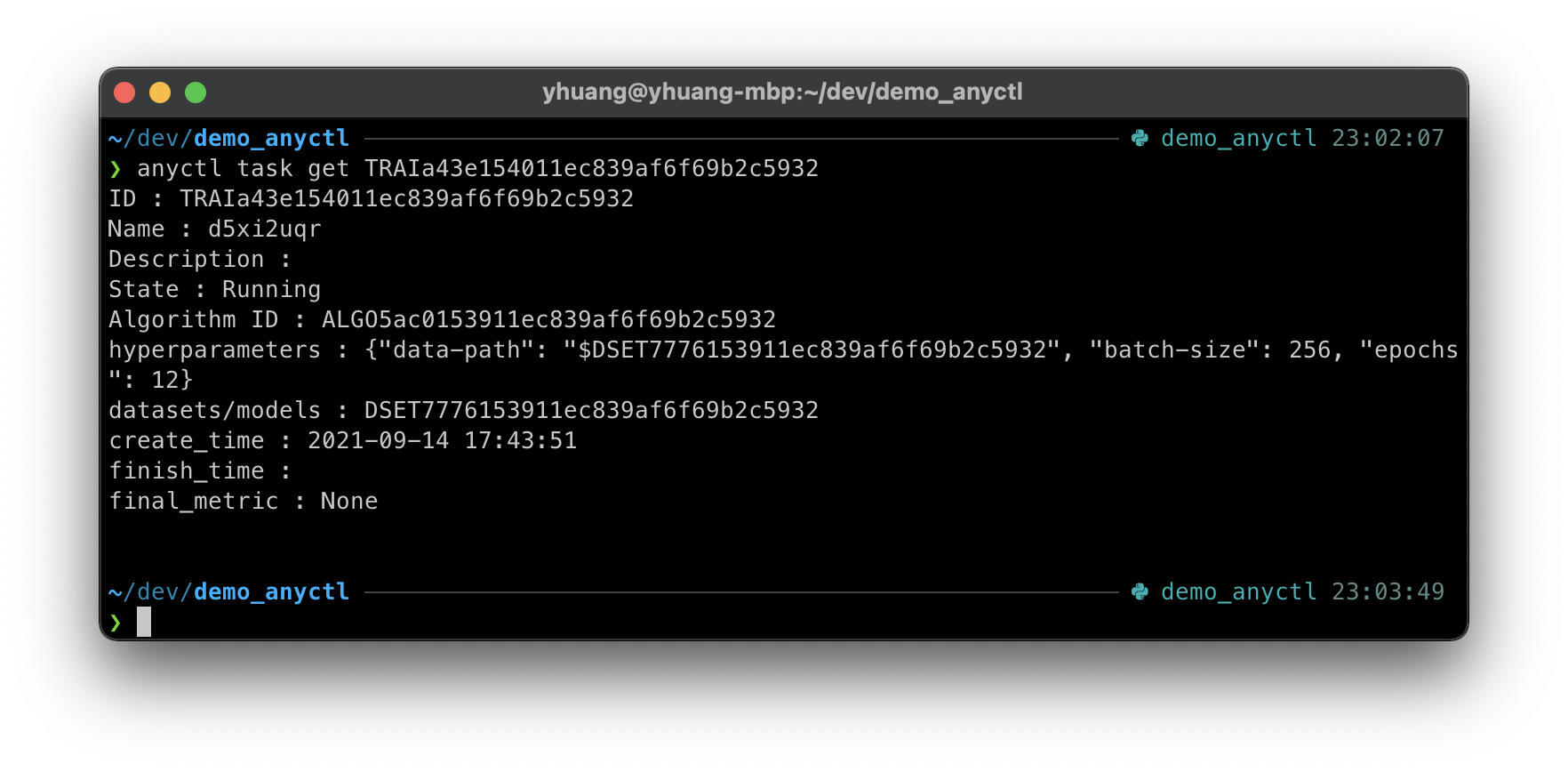
例如,用户可通过 anyctl task get 命令查询某一训练任务的详细元信息:
anyctl task get <task_id>
这里需替换 <task_id> 为真实值,运行后会有以下输出:
查看训练日志¶
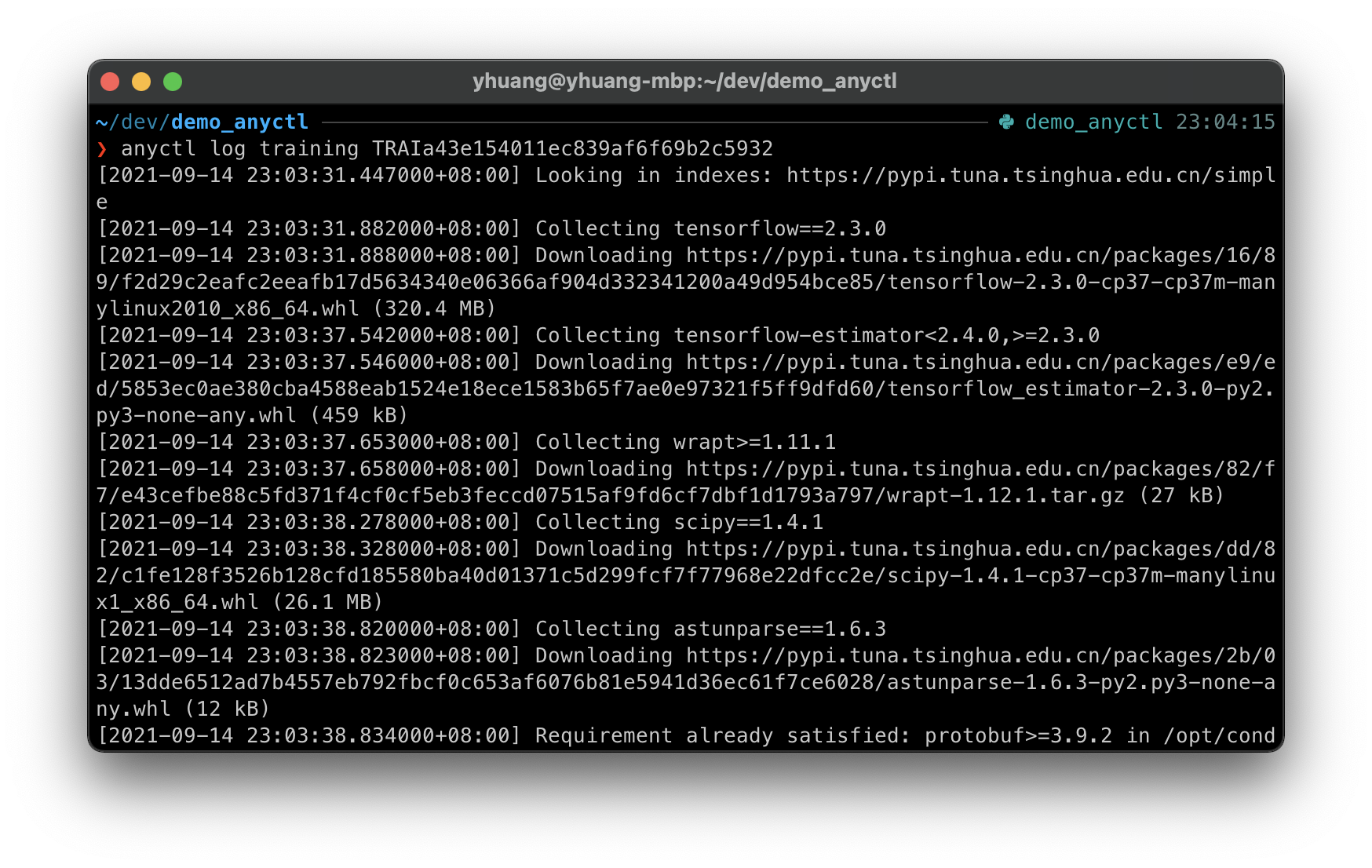
用户可以通过 anyctl log training 命令查看训练任务日志:
anyctl log training <task_id>
这里需替换 <task_id> 为真实值,运行后会有以下输出:
前往训练详情前端页面¶
用户可以通过 anyctl view task 命令打开浏览器并跳转到某一训练任务的详情页面:
anyctl view task <task_id>
用户可以通过前端进行更直观的日志查询、训练结果下载、模型转存、取消任务等操作。